Specifications¶
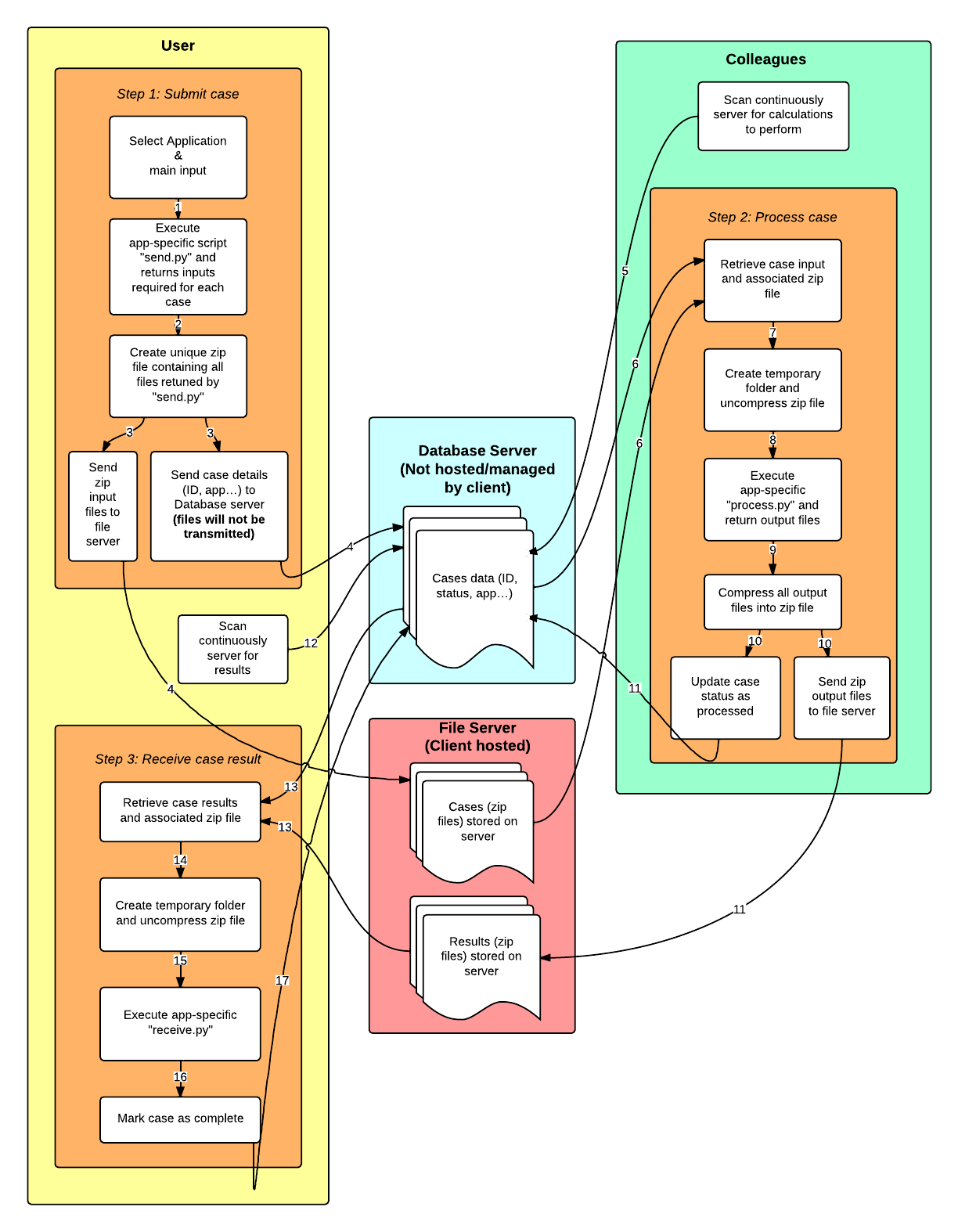
Architecture of Mongo Database¶
GridCompute communicates with a mongo database that contains all the details on cases. Following entries are present:
- collection cases
- _id: Unique Object Id based on timestamp of the case.
- user_group: User group. Ex: ENGINEERING DEPARTMENT.
- instance: Instance used to isolate grids. Ex: 0 or debug.
- status: Current status of the case. It can be to process, processing, processed or received.
- last_heartbeat: Timestamp of last heartbeat sent to notify the database that the process is still alive.
- application: Application associated to the case.
- path: Path on file server refering to input/output case.
- origin: Machine/User who submitted the case to the database.
- machine
- user
- time
- start: Time the case has been submitted to server.
- end: Time the results have been retrieved from server.
- processors
- processor_list: List of Machine/Users who tried to process the case (some attempts to process may have failed).
- machine
- user
- time (start and end) for the last attempt to process
- start: Time of the last attempt to process.
- end: Time the process returned.
- processor_list: List of Machine/Users who tried to process the case (some attempts to process may have failed).
- collection versions (optional)
- _id: Versions of program recognized by database.
- status: Can be either allowed, warning or refused.
- message: Message to be displayed when status is not allowed.
Application-specific scripts¶
Applications can easily take advantage of distributed computing by creating 3 scripts, as detailed in following sections.
Note
Some examples are present in template/Shared_Folder/Settings/Applications.
send.py¶
This script is executed when submitting cases to server. It takes as input a file selected by the user and returns one or several cases to submit to the server.
- send.select_input_files(filepath)¶
Submit a case to the grid.
This function returns, from a selected file, one or several cases to run. Each case can be made of several input files.
Parameters: filepath (str) – Path of the file selected. Returns: str list: A list (or tuple) of cases. Each case is a list (or tuple) of input files required to process a case.
process.py¶
This script is used to process cases. Its input is the ordered list of files submitted in send.py script. At the end of execution, a list of output files is returned, which is submitted to the server.
- process.process_case(input_files)¶
Process a case and return its results.
This function process a case from the grid and returns a list of output files that are sent back to the server. Process is executed in a temporary folder where all files are copied.
Parameters: input_files (str list) – ordered list (or tuple) of input files path. Returns: str list: An ordered list (or tuple) of output files to return to the server.
receive.py¶
This script is used to receive cases that have been processed, ie to specify what we want to do with the output files returned from process.py script.
- receive.receive_case(output_files)¶
Receive a case from the grid.
This function receives a case that has been processed on the grid. Process is executed in a temporary folder where all files are copied.
Parameters: output_files (str list) – ordered list (or tuple) of output files path. Returns: None.
Main code layout¶
For details on GridCompute source code layout, refer to Source code layout.